
然而,虽然市场上不乏优秀的独立游戏作品,但独立游戏与制作者的基数却也呈几何级的增长。如同知名独立游戏《人类一败涂地》制作人受访时表达的那样:做独立游戏的成功不啻于“中彩票”。一款亮眼的作品背后,通常是数十、甚至上百款默默无闻的游戏作为陪衬。即使是拥有5亿以上注册用户的Steam,也有约一半的游戏作品完全无人问津。
话说回来,有谁不希望自己的游戏会被玩家所喜爱呢?当制作者决定制作一款游戏,他并不是与某国或者某类作品互相竞争,而是与平台上数万款游戏相对比。抛开用户定位、宣发资源、游戏内容的因素不谈,在“自己想要的游戏”与“大家想要的游戏”之间想要达到高水平的糅合,很大程度上要依靠(甚至很多小团队只能依靠)上架前Demo或者EA阶段的用户测试与反馈。在这个流程中,不熟悉的制作者很容易陷入“实验者偏差”的困扰中。
实验者偏差
此处摘用第十版《社会心理学》的定义:
“研究参与者特别容易受到实验者的影响。实验者不管是有意还是无意的暗示他希望被试按照某一种方式反应,被试都会倾向于按照实验者的希望进行反应。被试会获得一些很微妙的线索,而这些信息会影响他们的行为。”
即强势方(实验者)对弱势方(受试者)的心理与行动存在一定量的潜在影响,进而影响到实验结果的客观性的一种偏差现象。
由于成本、时间等元素的限制,在独立游戏的制作、测试流程中,制作者通常不会组织较为大型的测试。大部分的独立游戏测试反馈来自于组内成员、熟人等强社交关系,并且实验目标以UI、Debug等技术面为主。在测试流程中,测试者通常会明确告诉受试者实验目的,而受试者将以实验目的为前提进行针对性实验。
那么,这样的后果是什么呢?
实验情境
让我们架构一个简单的实验情境:
实验情境1:作者A将游戏测试版给了自己的朋友B,希望B为自己测试。而B从A这里得到了很多游戏的相关信息,随后A得到反馈。
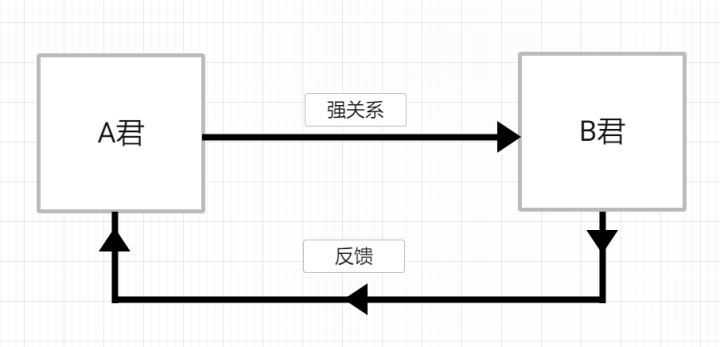
这个流程中,B作为A的友人,与A的信息差是非常小的;同时,B也高度认同A的游戏素质。此时,B的测试结果相当接近于A亲自测试,实验者偏差将会相当巨大。
在独立游戏的测试流程中,许多个人制作者或小团体将会止步于一个由若干“朋友B”组成的小团体中。这个“朋友B”有可能是组员、朋友、一切与A有着高度信息共享与社交关系的玩家。
结果非常显而易见。接近于若干个自己来进行测试的情况下,除了得到影响游戏的恶性BUG的反馈外,其他期望是非常低的。
由于B会受到A的强大影响、无意识暗示与大量信息,进而对大部分方向性问题能够理解与包容。这样的游戏测试,无论看起来有多少个B(几百个,甚至上千),都基本等同于1对1的实验。
那么,如果通过社交裂变进行测试流程,结果又会如何呢?
实验情境2:作者A将游戏测试版给了自己的朋友B,B又扩散到了B所处社交群体的玩家C与D。在这个过程中,B告诉C与D这是友人A的作品,并且给到了C与D游戏的各种信息;其中C喜欢这个游戏,测试完成了;而D测试途中因为各种原因半途而废了,或者直接拒绝了测试。于是B把C的测试结果反馈给了A。
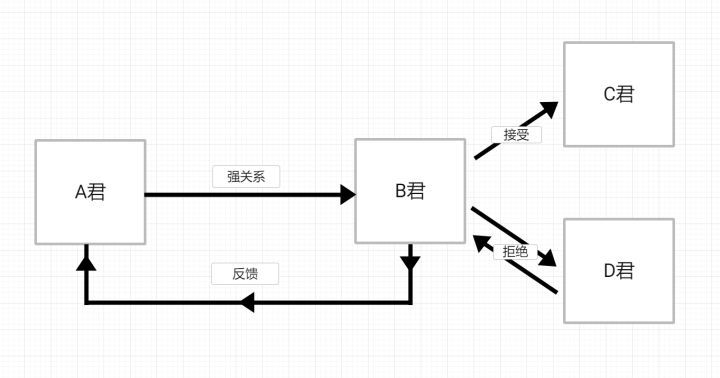
在这个流程中,信息在A-B-C间逐步流失,相比起B的位置,C的立场更为接近普通核心玩家。但无可置疑的是,C也接收到了B关于A的信息。这些信息,并非是普通玩家能够获得的。因此,在信息认知与理解方面,C是更靠近A的。
这种实验情况下,C等于弱化版的B,而D拒绝的信息被B所屏蔽了,并没到达A。假设C代表10人的群体,而D代表100人的群体,另一种有趣的偏差就出现了。
“没有结果”的这种结果消失了。
这种实验流程中,B作为收集反馈的中间环节,即传播学意义上的“把关人”。无论是线上测试、线下活动试玩等,均可以视为实验情境2的变型传播流程。当把关人有意无意屏蔽了可能占到绝大多数的无结果时,对于一款资源有限的独立游戏很可能就是致命一击。
原因
来看一个真实的例子:
游戏作者在内部测试阶段与线上测试阶段均取得了很好的口碑,甚至还在线下提供了试玩,得到玩家的好评。但在游戏上架后突然遭受了如潮差评,进入非常尴尬与迷茫的状态。
事实上,上面的这个事例就是实验情境1与2的复合,也是“反馈陷阱”的真实表现。最终形成实验者偏差的原因无非以下几点:
首先,游戏测试和正式发售,是实验者主动邀请传播到受试者/玩家被动接受平台与宣传的性质完全不同的两种阶段。
在主动邀请的阶段,实验者与受试者是先建立情感连接、再玩游戏,受试者是以玩完游戏为目标,且受到实验者的影响,目标非常明确;而正式阶段则要通过玩家先玩游戏,并且深入到一定程度,才能建立情感连接。玩家并没有必须完成游戏的情感驱动力,也并没有什么目标可言。将测试结果不加处理的认为是真实反馈,一定会出现结果上的偏差。
其次,实验玩家的信息量与实验偏差为正相关。
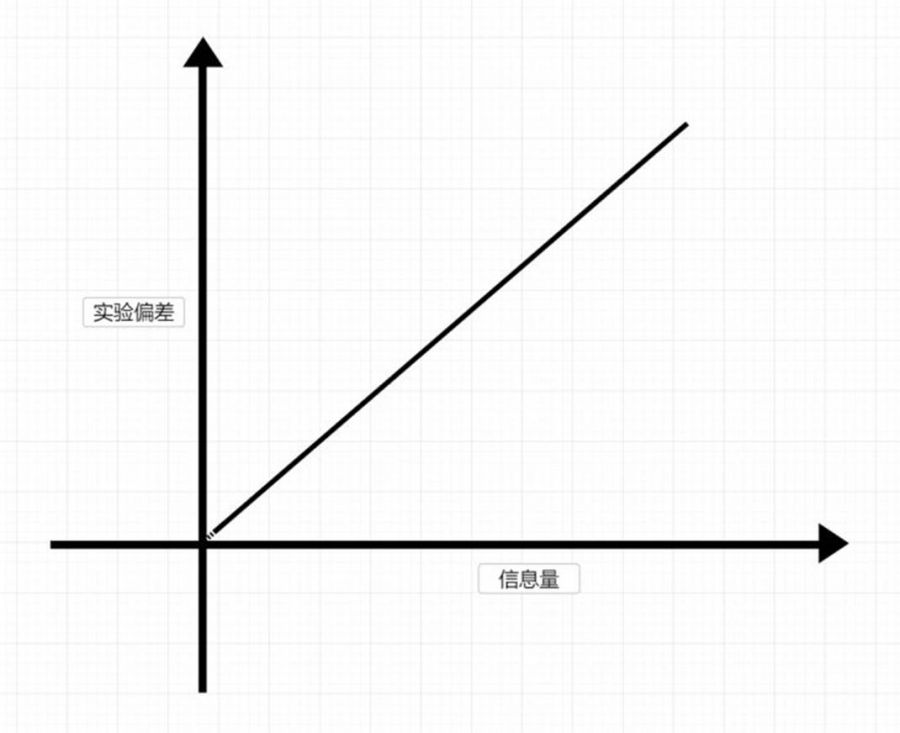
上面说到,真实玩家是被动接受宣传,接收到的信息量一定较少。换言之,在测试流程中,受试者的信息越少,就越接近真实的玩家。因此,测试的时候环境是否客观是非常重要的。腾讯与B站等游戏巨头,近年来不断的使用匿名测试方式,也印证了这一点。
其三,把关人的选择问题。
在实测流程中,无论是制作者自身或者是负责把关测评的团队成员,很容易只统计反馈的问题、提出反馈的人,而忽视无反馈、负面反馈、无意义反馈的情况,从而丢失反馈的完整结果。这样反馈回来的数据,仅代表一小部分、局部的意见,而无法从宏观去把控游戏的整体情况。
优化建议
如同在文章中多次提到的那样,独立游戏因为多因素局限,不可能像大作一样“大而美”,只能从“小而精”的方面着手。
那么,如果只有50或100人,甚至更小的受试者群体,制作者该如何避免踏入反馈陷阱,最大限度减少实验者偏差,得到最高的测试期望呢?
第一,游戏制作人要尽量减少自身信息量与情感联系对受试者的影响。
通过代理人或者机构,或通过匿名、“穿马甲”的方式,将游戏推送给受试的群体,使其在接近陌生的环境下进行测试,得到的反馈一定会比直接推送更为真实可信,减少因信息量造成的偏差。如果可能的话,可以在个人之外,夹杂立场中立的机构或者媒体,相信能够更贴切一些。
第二,重视整体反馈结果。
一个游戏不可能只有核心玩家,大部分玩家都属于普通玩家。因此,对浅反馈、无反馈结果的分析,也应该提到与正面、负面反馈相等同的位置。这样的统计方式,有利于制作人对游戏情况的整体把握。事实上,作为浅层用户最多的手游厂商,对用户停留时长、用户行为有着一套完整的分析方式。虽然大部分独立游戏无法做到精准的大数据分析,但是管中窥豹,从有限的受试者群体中抓取更多的信息,相信是有所裨益的。
第三,沟通流程要全面,完善。
测试流程中,“把关人”掌控着信息的上传下达,是很重要的职能。作为把关人,不仅要和制作人保持足够的信息交流,更要对受试者的结果进行总结与分析,并全面的反馈给制作人。而制作人并不是被动的接受信息,更要明确的主动从把关人方面获取完善的信息,并要求把关人注意细节,这样,在测试流程才能够最大程度的避免把关人无意识制造,或自己踏入“反馈陷阱”,及时修正游戏问题,避免尴尬情况的发生。
作者:黑羽
来源:GameDiary
专栏地址:https://zhuanlan.zhihu.com/p/77404747