
戴森球与行星级生产基地
目前这个存档的游戏时间是118小时。
游戏玩到后期卡吗?这也许是大家最关心的问题之一。
数千艘运输机在忙碌,数千座设施在运作,数万个太阳帆在环绕,数十万货物在运送,斗转星移,地面上所有太阳能板都面朝着太阳… 这计算量可不是闹着玩的!而以上还只是这一个星球。
本篇我将主要介绍为了保证游戏的流畅性,我们是如何实现游戏性能优化的。由于该话题涉及的内容与技术细节实在太多,所以我打算将优化系列分为三篇开发日志,粗略的谈一下我们所用的方法与技术。
游戏的帧率机制
游戏中的帧率分为渲染帧和物理帧:
渲染帧主要负责渲染游戏画面;
物理帧主要负责运行游戏逻辑。

我们在游戏中制作了帧率计数器以监控实时性能,其中左边的数字是渲染帧,右边的数字是物理帧。也可以在设置面板中设定渲染帧的帧速率。当开启垂直同步时,渲染帧速率会和显示器刷新率一致。

帧速率越高,GPU 的使用率也就越高,当使用率接近100%时,就会自动降低画面帧率。
在游戏的生产系统中,我们需要一套能精确量化,服从“决定论”的逻辑,即同样的操作只能导致同样的结果。要抛开帧率带来的影响,首先是游戏中所有的时间必须按物理帧计数,例如制造时间为3秒的“电弧熔炉”,其实在内部逻辑里就是180个物理帧。再例如360kW的工作功率,在内部逻辑里其实是每个物理帧消耗6kJ的能量,颇有一种“量子化”的感觉。

根据以上的逻辑,负责游戏逻辑的物理帧必须相对稳定,不能被渲染帧率所影响,否则玩起来就会感觉时间一会快,一会慢,所以我们将物理帧率锁定为60帧,只有当渲染帧率太低时,才会折减物理帧率,以免塞帧。
使用 DOP 来代替 OOP
DOP和OOP分别指“面向数据编程”和“面向对象编程”。具体的比较可以写好长一篇文章,而且前人已充分讨论,所以这里就不赘述了。简单来讲,在面对游戏中大量物件的情况下,面向对象会造成许多不必要的开销,造成性能低下,而面向数据编程则将对象中的属性逐一拆分出来,形成紧密排列的数组,使得相关逻辑能够更快速的进行遍历,甚至一些数据还能直接传给 GPU 来处理。
那么为什么大家不都用DOP来代替OOP呢?这是因为“面向对象”更符合人们的认知和代码书写习惯,也便于项目管理,而“面向数据”的代码写起来有一些反人类,有时甚至相似的结构写好几遍,不方便管理,但实际运行效率却极高。所以为了游戏的优化,我们还是选择了“面向数据”来作为该项目的编程核心思想与框架。
读起来太晦涩了吗?那实在不行的话我们就这样吧!

不开玩笑了,回到正题
物理帧的大部分工作是由 CPU 来完成的,要维持60的帧率,一个物理帧允许的 CPU 处理时间不能超过16ms(毫秒),除开提交DrawCall渲染的时间和其他必须的开销,只有大约11ms可用于一帧的游戏核心逻辑。
单核游戏?多核游戏?都不是,这是一个 GPU 游戏!
目前 CPU 的性能发展遇到了瓶颈,已经没办法再大规模提升单核性能,只能靠提升核心数量。而在很多实际应用的情况下,对核心数量的提升,远不如增加一点点单核频率提升的性能多。
虽然我们在星系的随机生成及模拟、星球地形动态生成、无缝加载等逻辑中使用了多线程来缓解主线程的压力,但是对于游戏逻辑中如此庞大的计算量,就算有100个核火力全开多线程完美配合也未必驾驭得了!
从《戴森球计划》的想法诞生之初,就决定了这是一个 GPU 游戏。看那数万颗太阳帆,每一颗的运动都遵循着万有引力定律,每一颗都在计算发电量,每一颗都能被近距离观看。像大规模并行计算这样的工作,使用 GPU 是不二的选择。

我们将凡是可以并行计算的那部分计算工作,全部交给了 GPU,剩下的那部分计算量,只要 GPU 能在16ms之内按时渲染出来,CPU 就绝不会掉链子!
这同时也意味着,好的 GPU 的确能为《戴森球计划》带来更流畅的体验,而 CPU 的影响则相对较小。
使用 GPU 来渲染大批量动画
在现今主流游戏引擎中,动画大多是靠移动部件或骨骼的位置(Position)、旋转(Rotation)、缩放(Scale)来完成的,如下图:
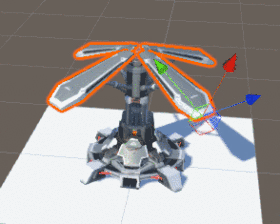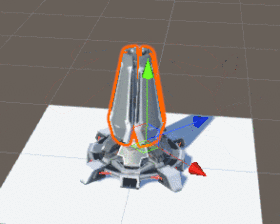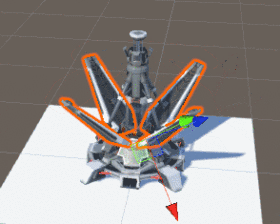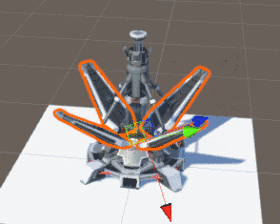
该建筑的动画是靠旋转移动部件来完成
就是这样一个建筑,它的动画部件已超过50个,其中还包括父子Transform层级的嵌套,假设我们有1000个这样的建筑,那 CPU 需要同时处理的动画子部件就有超过50000个,这显然是 CPU 驾驭不了的,而这还仅仅只是建筑动画,并不是核心逻辑。
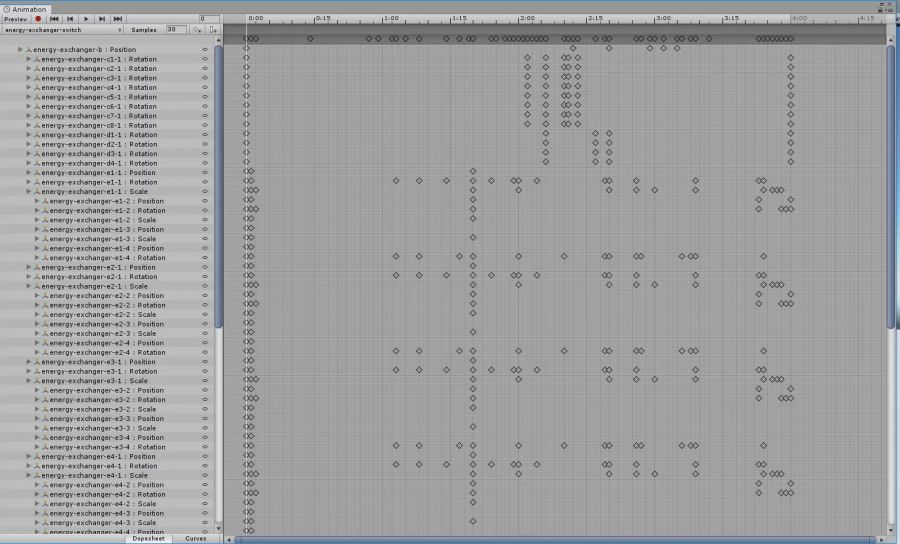
用 CPU 去逐一计算这50000个部件的 Transform 的确是相当不划算的,这些动画其实可以并行计算,只要在画面帧结束时,所有建筑的动画均就绪即可,这对于具有强大并行计算能力的 GPU 来说简直就是小菜一碟。
我们在编辑器中将这个建筑的所有动画帧中所有的顶点位置、法线等信息按照一定的顺序,事先录制在一个VERTA文件中。
当游戏加载时,只需要载入这些文件,通过ComputeBuffer将所有信息传递给 GPU,这样 GPU 就拿到了所有建筑动画的预烘焙信息,接下来再将每个建筑的动画状态组成一个数组,传给 GPU。
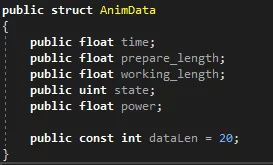
每个建筑的动画状态数据
最后,还需要在vertex shader中分析这些数据,逐一还原每个建筑在当前帧的建模。
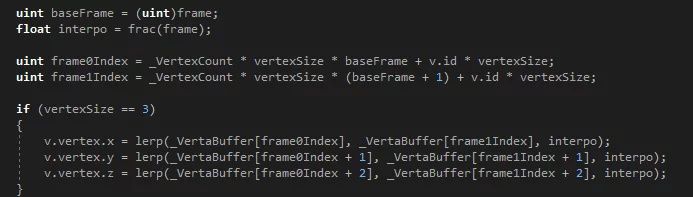
在vertex shader中还原当前帧建模部分代码

按照这个思路,我们成功使用GPU Instancing还原了所有建筑的动画,还顺便使用了建筑状态数据来控制建筑贴图上指示灯的开关。在动画和建筑状态更新方面,CPU 被完全解放。而在 GPU 中,仅仅只是多了 150MB 左右的显存数据用于存储所有建筑的动画数据(仅相当于几张4096贴图)与若干在vertex shader中的寻址与插值计算。可以说是一顿免费的午餐了!
粒子特效
为了将特效渲染纳入上面的框架中,所有的建筑特效均无法使用引擎自带的粒子特效,必须将原本是作为粒子来渲染的特效包含在模型网格中,再使用shader来逐一实现各个建筑不同的特效需求。

特效片元在制作时就包含在模型中
在游戏中,几乎每一个不同的建筑都定制了不同的shader,对于同一个建筑特效的不同片元,我们按照类别涂上不同的顶点色,哪些是辉光,哪些是要拉长的,哪些应该从下至上亮度递增,通过不同的片元顶点色,就能做不同的处理。

整个建筑的动作与特效在一个 shader 中实现
需要时刻朝向太阳方向的建筑,逻辑不能让 CPU 来处理。我们将建筑模型按照“底座”、“横向转动部分”、“俯仰转动部分”涂上不同的顶点色加以区分,再在shader里面计算这些顶点应该如何旋转,从而朝向目标点。
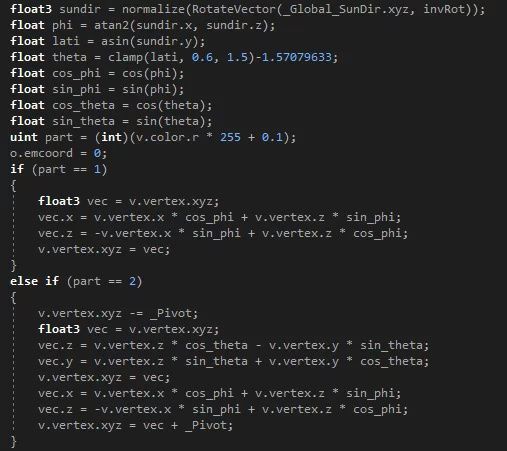
朝向太阳的shader代码节选
有了这套机制,我们就只需要在主线程中计算好每个建筑当前的状态,形成ComputeBuffer,传递给 GPU 来进行统一渲染,在这个过程中,动画、IK 朝向、特效、自发光变化等等,就统统都有了。
Unity Profiler 性能测试
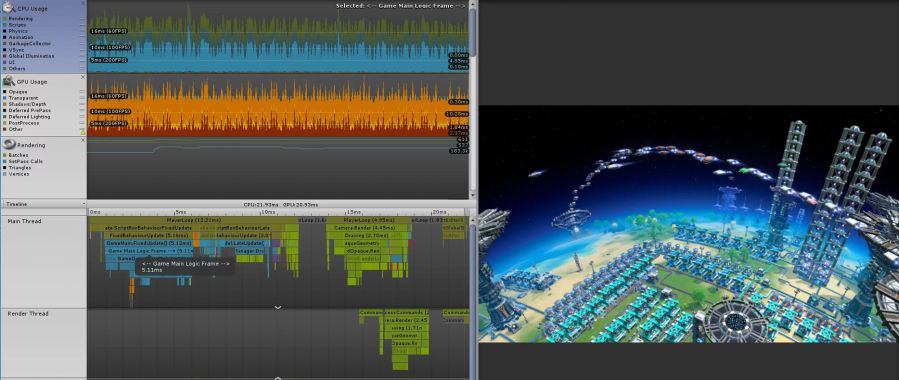
说了这么多,直接上目前的性能测试图吧!
下面是100小时规模的存档在 Unity Profiler 里面的性能测试图
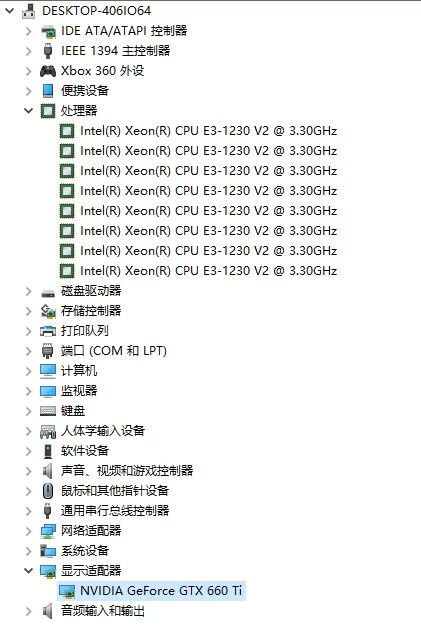
开发机配置
从图中可以看到,游戏主逻辑物理帧 CPU 耗时 5.11ms,也就是说理论上每秒可以跑到 195 个物理帧,所以 CPU 这边肯定是没问题,而最终画面能跑多少帧,就看 GPU 的能力了,我的卡是 660Ti,在畅玩了100小时后,还能跑上40帧,不过我们还将继续不懈的优化,争取将我这张卡的帧率提到 60!
除了物理帧的优化以外,我们还非常看重 C# 的垃圾回收机制的优化,因为过多的内存垃圾会导致游戏时常卡顿,严重影响游戏体验。
一般来讲,每次触发垃圾回收机制都会出现不同程度的卡顿,卡顿出现的频率取决于 GC Alloc 的大小,而每次卡顿的时间取决于数据结构的复杂度。
为了尽可能消除游戏卡顿现象,从立项开始,程序在数据结构上就严格把控,能用数组的地方用数组,尽量少的使用 Dictionary 或 List,凡是物理帧的逻辑除数组扩容等操作以外,均不能产生 GC Alloc,在 UI 逻辑中严格控制字符串的操作,避免不必要的开销。
据测试,目前游戏的 GC.Collect 卡顿时间已控制在 30ms 以内,出现频率为几乎没有。
下图为 100 小时规模下的 GC 性能统计:
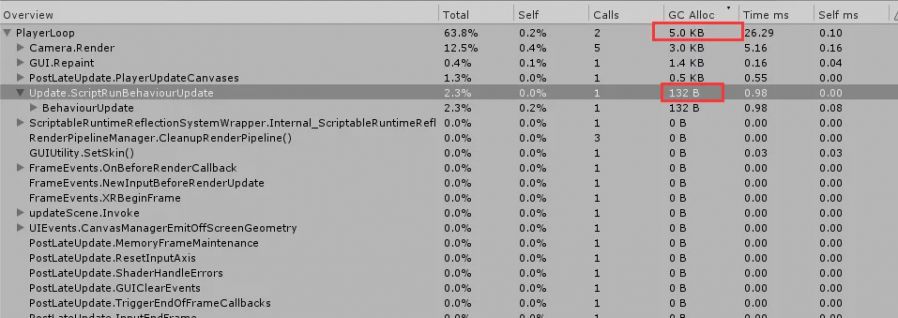
游戏主逻辑在物理帧上的 GC Alloc 为 0,只有 UI 上有 132 字节的开销,加上一些引擎必要的开销,每帧总的 GC Alloc 为 5.0KB,目前这个数值处于非常低的水平。
本篇完
在下一篇优化日志中我会介绍物流运输机、戴森云的优化,看看 GPU 是如何轻松达到“数十万”这个数量级!
来源:indienova
原文:https://indienova.com/indie-game ... on-sphere-devlog-4/