
标题图来自视觉中国
导读:
游戏中要不要加入高级人工智能?许多家电子游戏开发商对此犹豫不决,因为他们担心如此一来,会失去对整体玩家体验的控制。事实上,在电子游戏中,人工智能的目标并非创造一个不可战胜的实体供玩家与之对抗,而是要让玩家在长时间内最大限度地参与和享受游戏。
本文主要概述了电子游戏中的人工智能是如何随着时间的推移而发展的,以及目前在游戏中的应用。
大多人可能会认为,在最近几年发行的大多数游戏中,那些非玩家控制的角色、生物或动物(本文通常称为机器人)都有高度复杂的人工智能。然而,游戏中要不要加入高级人工智能,许多家电子游戏开发商犹豫不决,因为他们担心如此一来,会失去对整体玩家体验的控制。事实上,在电子游戏中,人工智能的目标并非创造一个不可战胜的实体供玩家与之对抗,而是要让玩家在长时间内最大限度地参与和享受游戏。
如果你选择了一款新游戏并开始进行游戏,你的游戏乐趣,会不会一次又一次地被彻底摧毁呢?又或者,你愿意与和你水平相似或更高的人配对吗?这样随着时间的推移,你就能不断学习和进步。绝大多数玩家可能会选择后者。但这并不意味着人工智能在现代游戏产业没有立足之地,只是意味着人工智能在电子游戏中的用途,与我们最初期望的有所不同。我们不想创造最好的人工智能,我们想创造的是最令人愉快的人工智能,能够让玩家与之互动或竞争。
电子游戏中人工智能的历史
人工智能是一个非常宽泛的术语。它不一定需要是一个从玩家行为中学习的模型。《德军总部3D》(Wolfenstein 3D)早在1992年就发布了,就连游戏中的士兵也有一个基本的人工智能形式。有限状态机(Finite State Machine,FSM)算法是一种相对简单的人工智能,设计者在其中创建一个机器人可以经历的所有可能事件的列表。然后,设计者分配机器人对每种情况的具体响应(Lou,2017年)。我们可以想象,在1992年,《德军总部3D》的开发者考虑了敌军可能遇到的所有情况。在他们的视野之内,一扇门可能会打开,Blazkowicz(《德军总部》系列游戏中的英雄)可能会走进他们视野内,他们可能会从他背后开枪射击,他们也有可能看不到Blazkowicz,等等。开发人员会编制这个列表,并针对每个情况,告诉机器人应该去做什么。这是Lou的文章中一张有用的图片:
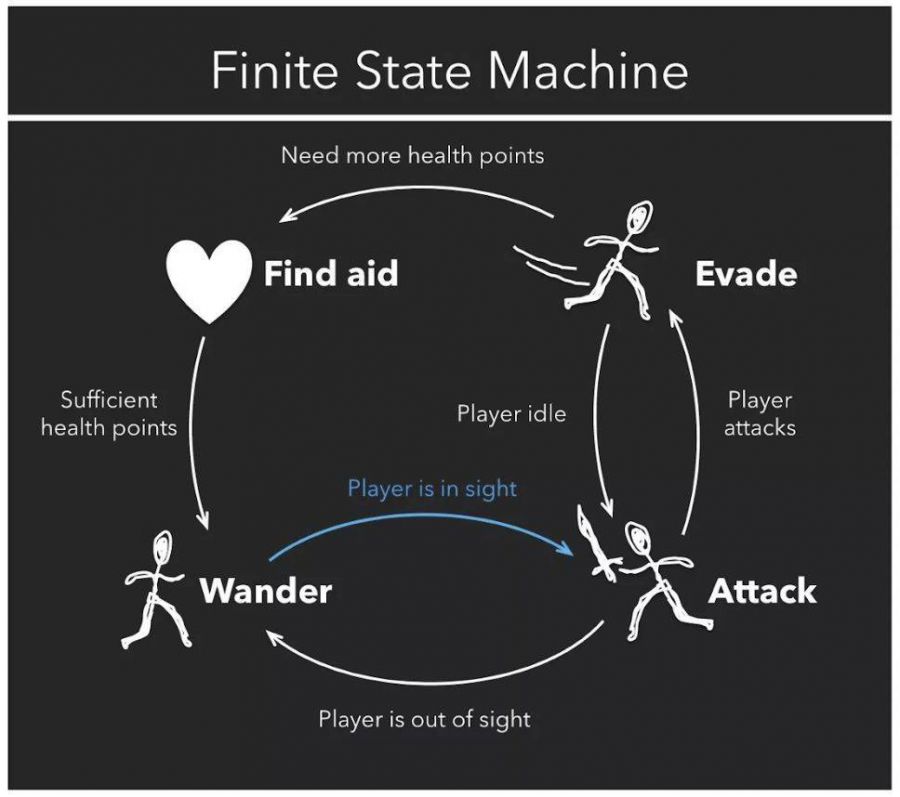
图1(Lou,2017年)
这显然是一个简单的例子。我们可以想象得到,构建的细节越多,它就会变得越复杂。机器人在放弃之前应该搜寻Blazkowicz多长时间?如果他们放弃搜寻,他们应该待在原地呢,还是回到生成点呢?这个列表会很快变得非常冗长,而且非常详细。在有限状态机中,创建游戏的开发人员将为每种情况分配一个特定的动作。
译注:有限状态机是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型,一种用来进行对象行为建模的工具,其作用主要是描述对象在它的生命周期内所经历的状态序列,以及如何响应来自外界的各种事件。状态存储关于过去的信息,就是说:它反映从系统开始到现在时刻的输入变化。转移指示状态变更,并且用必须满足确使转移发生的条件来描述它。动作是在给定时刻要进行的活动的描述。有多种类型的动作:进入动作(entry action):在进入状态时进行。退出动作:在退出状态时进行。输入动作:依赖于当前状态和输入条件进行。转移动作:在进行特定转移时进行。在计算机科学中,有限状态机被广泛用于建模应用行为、硬件电路系统设计、软件工程、编译器、网络协议和计算与语言的研究。
《德军总部3D》游戏截图
有限状态机算法并不适用于每款游戏。试想一下,如果在策略游戏中使用有限状态机会发生什么?如果机器人被预编程,每次都以同样的方式做出响应,那玩家将会很快学会如何智胜计算机。这就产生了重复的游戏体验,正如你所预料,这并不会让玩家感到愉快。为了防止有限状态机的重复性,人们提出了蒙特卡洛树搜索(Monte Carlo Search Tree,MCST)算法。蒙特卡洛树搜索的工作方式是首先可视化机器人当前所有可用的动作。然后,对于每个可能的动作,它分析玩家可能会做出响应的所有动作,然后它会考虑所有它可能做出的响应动作,等等(Lou,2017年)。你可以想象这棵树将会以多快的速度变成“参天大树”。下面是一幅很不错的图表,可以直观地了解蒙特卡洛树搜索是如何工作的:
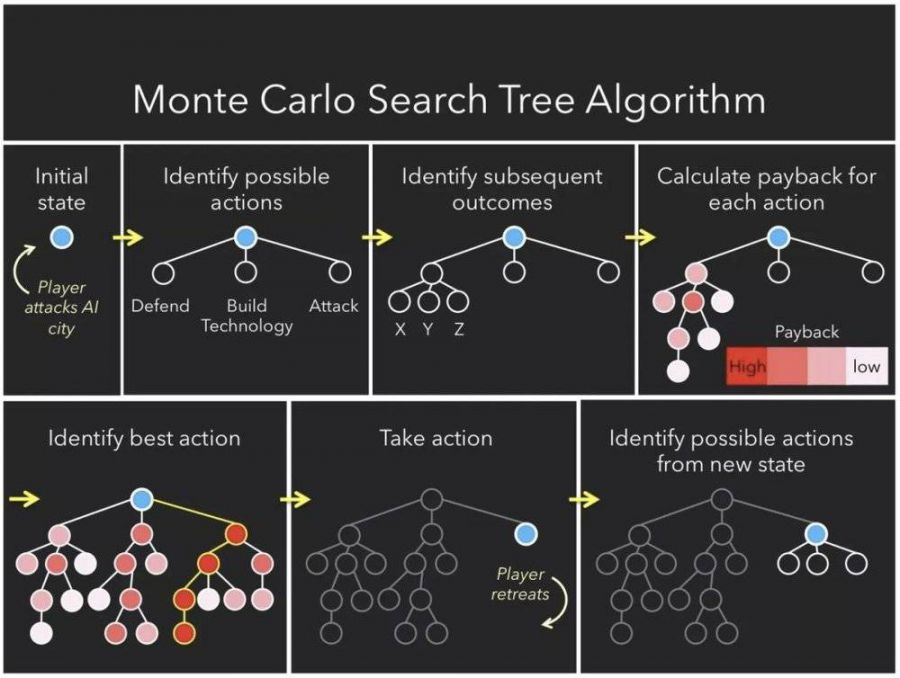
图2(Lou,2017年)
图2突出显示了使用蒙特卡洛树搜索的计算机在针对人工组件采取动作之前所经历的过程。它首先要查看它拥有的所有选项,在上面的示例中,这些选项要么是防御,要么是构建技术,要么是攻击。然后,它构建了一棵树,预测此后每一次潜在动作成功的可能性。上面我们可以看到成功率最高的选项是“攻击”(因为暗红色表示更高的奖励概率),因此计算机选择攻击。当玩家进行下一步动作时,计算机将重复树的构建过程。
译注:蒙特卡洛树搜索树是一种用于某些决策过程的启发式搜索算法,最引人注目的是在游戏中的使用。一个主要例子是计算机围棋程序,它也用于其他棋盘游戏、即时电子游戏以及不确定性游戏。蒙特卡洛树搜索并不是一种"模拟人"的算法。而是通过随机对游戏进行推演来逐渐建立一棵不对称的搜索树的过程。可以看成是某种意义上的强化学习,当然这一点学界还有一些争议。这个算法可以追溯到20世纪40年代。蒙特卡罗树搜索大概可以被分成四步:选择(Selection)、拓展(Expansion)、模拟(Simulation)、反向传播(Backpropagation)。
想象一下像《文明》(Civilization)这样的游戏,一台计算机可以做出的选择该有多少啊。如果要为整个游戏的每一个可能的选择和每一个可能的场景构建一个详细的树,计算机将会花费极其漫长的时间。它永远不会采取行动。因此,为了避免这种海量的计算,蒙特卡洛树搜索算法将会随机选择一些可能的选项,并仅为所选择的选项进行构建树。这样,计算就会快得很多,而且计算机可以分析出选择哪一种选项获得最高奖励的可能性。

《文明》游戏截图
《异形:隔离》中的人工智能
最近电子游戏中比较流行的高级人工智能形式之一是来自Creative Assembly开发的《异形:隔离》(Alien:Isolation)中的异形。人们对人工智能在幕后是如何工作的,存在一些误解。然而,这是一个引人注目的展示,展示了人工智能如何为玩家创造一个引人入胜的、不可预测的环境。
《异形:隔离》中的异形,有两种控制其运动和行为的人工智能力量:人工智能导演和人工智能异形。人工智能导演是一个被动控制器,负责创造一个愉快的玩家体验。为了做到这一点,人工智能导演一直都知道玩家和异形在哪里。但是,人工智能导演并不与游戏中的异形分享这些情报。人工智能导演密切关注所谓的“威胁量表”,它本质上只是度量预期玩家压力水平的一种指标,由多种因素决定,例如异形接近玩家的距离、异形在玩家附近的时间、在玩家面前的时间、在运动跟踪器设备上可见的时间等等。这个“威胁量表”告知异形的工作系统,它本质上只是异形的任务追踪器。如果威胁指标达到某个级别,任务“搜索新位置区域”的优先级将会增加,直到异形离开玩家进入一个单独区域。

《异形:隔离》游戏截图
行为决策树
在深入了解人工智能异形的运行原理之前,重要的是首先要强调影响决策过程的结构。人工智能异形使用了一棵广泛的行为决策树,这棵树包含超过100个节点和30个选择器节点。想象一下下面的简单例子:
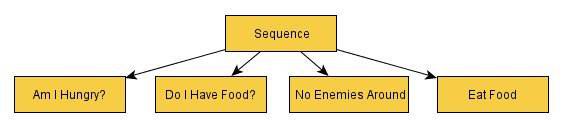
图3(Simpson,2014年)
行为树的工作方式是从左到右询问问题。一个成功允许沿着树前进,而失败将会返回到序列节点。过程如下:序列→我饿了吗?(成功)→序列(运行)→我有食物吗?(成功)→序列(运行)→周围没有敌人(成功)→序列(运行)→吃东西(成功)→序列(运行)→父节点(Simpson,2014年)。如果在任何时刻,其中一个节点返回(失败),那么整个序列都将会失败。例如,如果结果是“我有食物吗?”失败了,它就不会再检查周围是否有敌人,也不会再吃东西。相反,这个序列将会失败,而这将是该序列的结尾。
序列显然可以变得更加复杂,并在深度上成为多层次。下面是一个更深层次的例子:
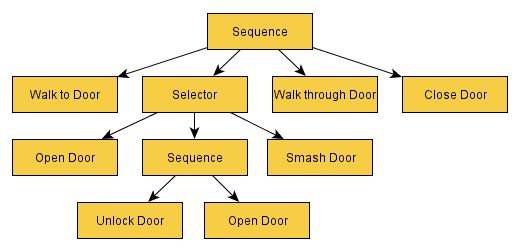
图4(Simpson,2014年)
记住,当一个序列成功或失败时,它会将结果返回给它的父节点。在上面的例子中,我们假设我们已经成功接近了一扇门,但并没有打开门,因为门是锁着的,我们没有钥匙。那么序列节点将被标记为失败。结果,行为树路径返回到该序列的父节点。下面是父节点的样子:
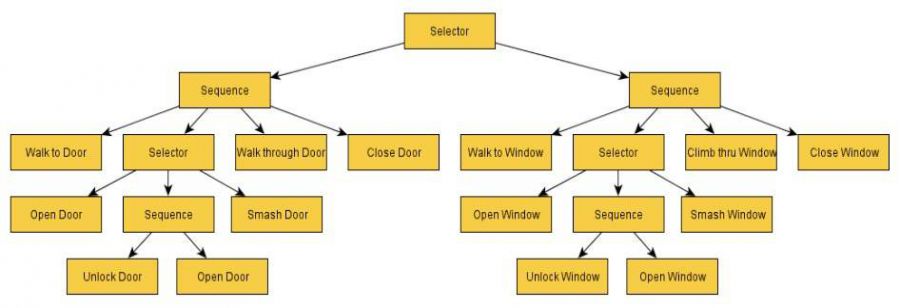
图5(Simpson,2014年)
所以,我们没能打开一扇门,但我们也没有放弃。我们的父节点还有另外一个序列供我们去尝试。这次它涉及到通过翻窗进入。人工智能异形有30个不同的选择器节点和100个总结点,所以它比这个例子要复杂得多,但我希望这能让你能够了解人工智能异形在后台究竟是如何工作的。
回到人工智能异形
正如我们所知,人工智能异形是控制异形行动的系统。它永远不会提供有关玩家位置的信息。它从人工智能导演哪里得到的唯一信息是它应该搜索的大致区域。除此之外,它必须自己找到玩家。它确实有一些工具可以帮助它找到玩家。第一个是传感器系统,它可以让异形感知周围环境中的音频和视觉线索,诸如脚步声、枪声、开门声,甚至是运动追踪器的哔哔声等噪音,所有这些都有助于异形追踪玩家。音频范围取决于所创建的噪音类型。除了音频传感器外,异形还能接受视觉传感器,比如看到Ripley跑过去,或者看到视野中有一扇门被打开,等等。
异形追踪玩家的另一个工具是搜索系统。有一些特定区域,开发人员已经确定是很好的隐藏点,异形是预编程好进行搜索的。但是,它并不会按任何特定顺序对它们进行搜索,甚至会再次检查已经访问过的区域。当然,如果异形听到噪音或看到了视觉提示,它就会搜索开发人员没有明确列出的区域。
关于《异形:隔离》最常被讨论的话题是:随着游戏的进展,异形似乎对玩家有了更多的了解。当它学习玩家游戏风格的某些特征时,它所做的动作似乎变得更加复杂。令人惊讶的是,开发人员实现这一目标的方式,并不是通过在异形的人工智能中构建一个复杂的神经网络来实现的。为了展示这款游戏如何实现这种异形的学习,我们需要回顾一下人工智能异形的行为决策树。
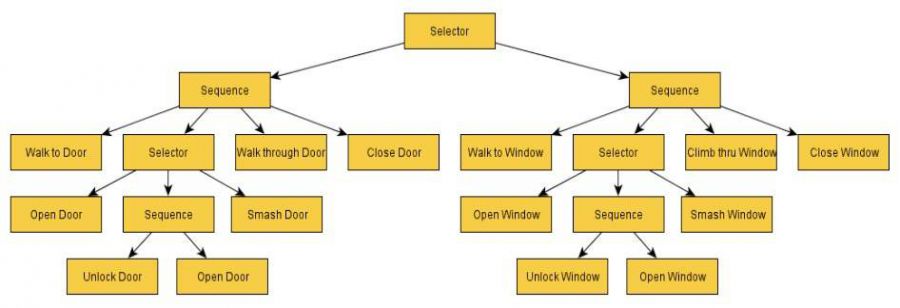
图6(Simpson,2014年)
在游戏开始的时候,这个行为树的某些部分对异形屏蔽了。被屏蔽的区域是异形无法访问的,这意味着异形无法访问某些行为和行动。例如,在游戏开始时,响应远处开门声音的树的部分可能不会处于活动状态。如果玩家在异形的视野中打开了一扇门,它就可以解锁行为树的那一部分,这样,将来打开门的声音会触发某个响应。随着玩家在游戏中的进展,越来越多的异形行为树被解锁。这就给人一种错觉,异形似乎正在学习并适应玩家的游戏风格。
电子游戏中的遗传神经网络
如果不提及神经网络在电子游戏中的应用,那么这篇文章就是不完整的。最近有一些非常著名的例子,其中一个就是击败了专业Dota 2团队的人工智能。然而,讨论这一主题的最好方法是从小处着手,对神经网络如何学习电子游戏的目标和策略有一个基本的了解。

图7(Comi,2018年)
为了达到这个基本的了解的目的,我们将使用的游戏是《贪吃蛇》(Snake)。对那些不熟悉这款游戏的人来说,贪吃蛇是一款2D游戏,在这款游戏中,你可以控制一行方块(即贪吃蛇)。你有三种动作选择:向左、向右或直走。如果你碰到墙上或者撞到你的蛇尾巴,你的蛇就会立即死亡并重新开始。有一个点可以去收集(称为食物),它会让你的蛇尾巴增加一个方格,所以你收集的点越多,你的蛇就会变得越长。
让我们想象一下,我们想教贪吃蛇如何获得尽可能高的点数,贪吃蛇要想在这个世界上生存,它就需要学习一些东西。为了让贪吃蛇学会,需要提供有关环境的信息,我们将把提供的这些信息作为输入。这些输入可以是我们掌握的任何信息。例如,我们的输入可能是以下6个是非问题:直走是否无碍、向左是否无碍、向右是否无碍、向前是否有食物、向左是否有食物、向右是否有食物(Designing AI,2017年)。根据每个问题的答案,这将为6个输入节点设置1或0。然而,这些输入也可以是测量蛇头到墙壁或蛇尾,或食物之间的距离。为简单起见,让我们继续看6个输入节点的例子。
接下来我们需要告诉贪吃蛇我们想要它实现什么目标。为了传达我们期望的目标,我们实施了奖励系统。例如,我们可以给贪吃蛇这样的奖励:每次向食物移动一步奖励1分,每次吃到食物并增加长度就奖励10分。然而,当Binggeser(Designing AI,2017年)为他的贪吃蛇实施这些奖励时,他意识到贪吃蛇只会在一个非常小的圈子里移动。这样,他的贪吃蛇就能在避开墙壁和长尾巴带来的危险的同时积累点数。很显然,这并不是我们预期的结果。在初始模型中需要加入某种惩罚,当贪吃蛇离开食物时,点数就会减少。这就鼓励了贪吃蛇主要向食物的方向移动。
现在我们有了一条能够从环境中获取信息的贪吃蛇,还有一个定义贪吃蛇目标的奖励系统。我们接下来该怎么办?我们的贪吃蛇如何真正学会如何进行游戏?在这一点上,快速了解一下神经网络实际是如何工作的将会有所帮助。
世代神经网络
世代神经网络的结构与标准神经网络的结构相同。它从一定数量的输入节点开始,然后输入到一个或多个隐藏层,最终提供一个输出。下面是一个很好的可视化示例:
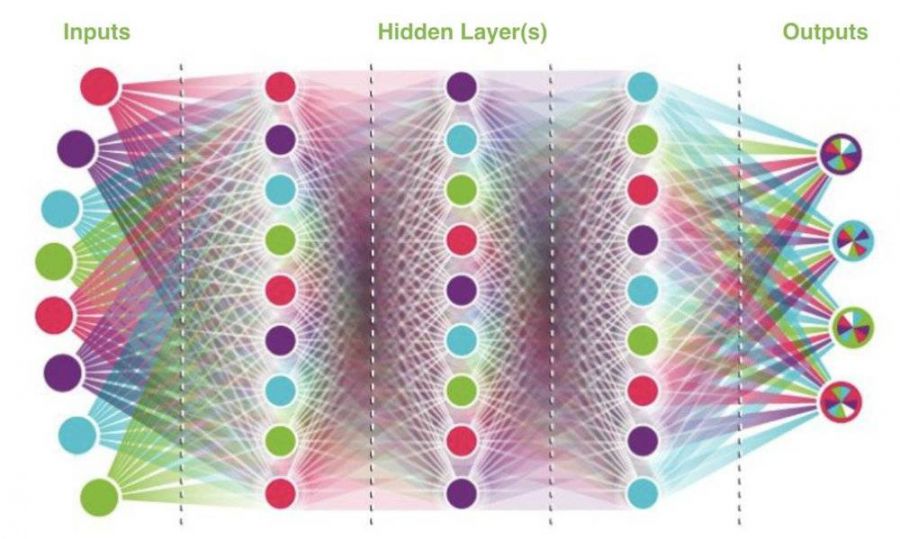
图8(Comi,2018年)
以我们的贪吃蛇为例,我们有6个输入节点,这些是我们之前定义的6个是非问题:直走是否无碍、向左是否无碍、向右是否无碍、向前是否有食物、向左是否有食物、向右是否有食物。每个输入节点通过我们成为权重连接到每个第一个隐藏层节点。在图8中,我们看到连接到每个节点的所有线(权重)。这些权重是我们的模型将要调整的,因为它知道哪些输入要加强或削弱,以提供最准确的输出。在我们这个例子中,“最准确的输出”被定义为“收集点数最多的贪吃蛇”。请记住,我们的贪吃蛇在靠近食物时会得到点数,在吃到食物时会得到更多的点数,离开食物时点数会减少。
世代神经网络“学习”的方式是首先确定每一代的大小(假设我们希望每代都包含200条贪吃蛇)。接下来,它为第一代的200条贪吃蛇中的每一条创建权重的微小变化,然后运行第一代的200条贪吃蛇中的每条蛇,并选择最终成功的蛇(即获得点数最多的那条蛇)。假设我们选出了第一代点数最多的前10条蛇(前5%)。这10条蛇随后将成为第二代的“父母”。这10条蛇的权重用于定义第二代的起点。第二代200条蛇将再次在这些权重上产生微小的变化,表现最好的蛇将被选为第三代的“父母”,以此类推。
回到贪吃蛇
因此,正如我们上面所看到的,我们可以反复运行第一代贪吃蛇模型(上面我们运行了200次),通过稍微改变每个权重,可以看到贪吃蛇产生的各种变化。然后,我们选择最佳表现的蛇,继续影响第二代神经网络权重。我们对每一代都重复这一过程,直到贪吃蛇的学习率开始趋于平稳(换句话说,直到世代的进步放缓或停止)。
也许在第一代、第二代和第三代中,没有一条贪吃蛇吃过食物,因此它从来不知道吃掉食物会奖励10分。然而,也许在第四代,有一条贪吃蛇吃了食物。这条蛇很可能有了它这一代蛇中最高的点数,因此被选中来影响下一代。后代的权重将基于最成功的贪吃蛇祖先而改变。经过10代、100代甚至1000代之后,你可以想象会发生多少次学习。
电子游戏人工智能在现实世界中的应用
在电子游戏行业中使用的同样类型的强化学习方法,也正成功应用于其他行业。例如,《侠盗飞车》(Grand Theft Auto)游戏已经被用来为测试自动驾驶汽车算法提供一个安全和现实的环境,这款游戏预编程了交通规则、道路和汽车物理学(Luzgin,2018年)。与现实世界相比,在虚拟环境中收集数据不仅安全和现实,而且速度还快了1000倍(Luzgin,2018年)。

《侠盗飞车》游戏截图
“电子游戏是训练人工智能算法的一种很好的方式,因为它们的设计目的是让人类思维逐步向更困难的挑战迈进。”(Luzgin,2018年)
人工智能在电子游戏领域的最新进展之一是由Open AI的研究人员完成的。Open AI基于一种算法创造了一款游戏,其唯一目的就是带着自然的好奇心去探索。奖励系统侧重于奖励探索而不是更深入进行游戏。研究人员将这个由好奇心驱动的模型放入《超级马里奥兄弟》(Super Mario Bros)游戏中,纯粹出于好奇心,它成功通过了11关。显然,这样做也有缺点,因为它需要巨大的算力,而且机器很容易“分心”。然而,对于第一次玩这款游戏的人类玩家来说,也是一样的。正如Luzgin在他的文章所引用的:“婴儿似乎采用无目标探索来学习技能,这些技能在日后的生活中将有用。”这种无目标探索的感觉贯穿一生,但最明显的例子还是通过电子游戏来探索虚拟环境。

《超级马里奥兄弟》游戏截图
总结
在今天的电子游戏行业中,人工智能的使用形式有很多。无论是简单的有限状态机模型,还是从环境反馈中学习的高级神经网络,这些虚拟环境为人工智能的发展提供了无限的可能性(无论是游戏行业还是其他领域)。
参考链接:
Binggeser,Peter.Designing AI:Solving Snake with Evolution_.2017.https://becominghuman.ai/designing-ai-solving-snake-with-evolution-f3dd6a9da867
Comi,Mauro.How to teach AI to play Games:Deep Reinforcement Learning_.2017.https://towardsdatascience.com/how-to-teach-an-ai-to-play-games-deep-reinforcement-learning-28f9b920440a
Lou,Harbing.AI in Video Games:Toward a More Intelligent Game_.2017.http://sitn.hms.harvard.edu/flash/2017/ai-video-games-toward-intelligent-game/
Luzgin,Roman.Video Games as a Perfect Playground for Artificial Intelligence_.2018.https://towardsdatascience.com/video-games-as-a-perfect-playground-for-artificial-intelligence-3b4ebeea36ce
Simpson,Chris.Behavior Trees for AI:How They Work_.2014.https://www.gamasutra.com/blogs/ChrisSimpson/20140717/221339/Behavior_trees_for_AI_How_they_work.php
Thompson,Tommy.The Perfect Organism:The AI of Alien:Isolation_.2017.https://www.gamasutra.com/blogs/TommyThompson/20171031/308027/The_Perfect_Organism_The_AI_of_Alien_Isolation.php
作者介绍:
Laura E Shummon Maass在医疗保健领域工作已有4年,从事数据分析工作,通过有意义的见解来促进变革。她自述数据是她的激情所在,希望她的文章能够激励他人。
作者:Laura E Shummon Maass
编译:Sambodhi
来源:AI前线(ID:ai-front),
原文链接:Artificial Intelligence in Video Games
https://towardsdatascience.com/artificial-intelligence-in-video-games-3e2566d59c22